0%
2021 年底来扯扯淡(下)
又是一个上午请假的日子,想起来之前的年底扯扯淡的文章挖了个上、下篇的坑,现在来填上。
日子一天天的过去,转移重心后的生活和工作都仍然在继续。
尝试 像 2021 年底来扯扯淡(上) 结尾说的那样的方式,遵从自己思考判断来做决定,而不是一味的为了工作里各种各样的公司战略、KPI、绩效而委曲求全着做一些其实毫无意义的事情。吃了很多年的饼之后,我终于意识到并且坚信:这些人并不是一个好的画饼师傅,而绝大数情况下,他们自己也心知肚明。
而在意识到这个情况之后,我也突然发现之前多年的工作里,一直是“偷懒”式工作,很长的时间里,甚至到了自我感动的地步。那时每天都很忙:
哇啊,公司又有了新的项目孵化目标了,加油啊,赶紧开发部署;
是啊,领导又有了新的方向想要尝试了,等不了,赶紧加班上线;
对啊,产品叕有了新的想法急需验证了,最终版,无脑迭代上架。
…
反反复复,无休无止。
那我就只管努力(偷懒)就好了啊,还思考啥。
忙吗?确实忙。可是永远是在为别人忙啊!
我就像个兵线上的小兵,永远固定路线、固定速度,被英雄们带着节奏漫无目的的走着、攻击着,然后倒下,最后还是变成别人的升级经验,并且不断重复。
就这样,一晃好多年。
“那能怎么办呢?”
是啊,那能怎么办呢?很多次和自己、和别人的聊天里,都会有这个疑问。被带着节奏太久了,无脑忙碌太久了,我们已经习惯了,甚至麻木了。太累了,太忙了,不想思考了。
只是每每总有那么一个时刻,我看着斧王的巨斧就在想:总有人要成为的英雄,为什么不能是我呢?
或者退一步,即使我终究是一个小兵,那我为啥不做一个有自己节奏的小兵呢?
那一刻,我的视角终于开始切换。
于是,我总结出了可能是我的人生迄今为止最重要的一个结论,并决定当做我的人生的第一优先级的奥义:
不论工作还是生活(当然还有 DOTA ),永远要保持自己的节奏!
基于自己当前的现状简单的分析之后,确认可能产生的影响和最坏的结果,感觉一切OK,我开始深信不疑的践行。顺带着,啪!我打开了那个情绪开关。
所谓树立中心思想,大刀阔斧改革,战略上藐视一切画饼师傅,战术上细化自己的目标和节奏,以此为前提,毫不迟疑的拒绝掉一切不合理的要求。
“什么,临时有项目需要交接要出差一段时间?”
“我不去,安排其他同事吧”
“什么,有个紧急的需求需要支持下?”
“当前在做需求,直接提个领导排好优先级”
“什么,项目紧急需要缩短工期加班?”
“周末有安排,不加班,自己去找领导协调”
还是那句话,一切的紧急都是基于你的节奏:who TM cares!
按照这个节奏工作下来,发现真TM爽啊!而且,最后你会发现,其实也不会有什么大影响。甚至于,保持“强硬”的态度之后会发现,之前不好沟通协调的事情竟然也开始变得容易了起来。人性从来就是这样。
所谓,好好先生并不能让结果事事好好。讨好型人格更是毫无必要。
只是,性格潜移默化,改变无法一蹴而就,意识到就好,慢慢改善。
工作学习节奏调整好了之后,接下来可能就是发育期吧,一切还是要慢慢来。
这个时候,我遇见了我的那个她。
懂得我说的:
“不要回答! 不要回答!! 不要回答!!!”
梗的她。
懂得大刘笔下
“只送大脑!”
的疯狂和浪漫的她。
这让我不得不感慨缘分的奇妙。甚至后面我回想起来,很难想清楚这是不是得益于我这段时间的想法改变之后整个人生活状态的蜕变。不能早,也不能晚,只能是这个时候的遇见才是最正确的时机。
回想着不知道从多久远的以前起,初中?高中?,我被每日负面、悲观、绝望的情绪裹挟着。在快要不堪重负而垮掉时,我开始有意识的训练自己的情绪。我想把自己机器化、数字化,想象着自己的大脑中有一个情绪开关。
啪!关闭它,啊,真好!我不再有任何的情绪了。
啪!打开它,啊,呼吸,忍受无数汹涌如潮水般的情绪把我吞没!
就这样,一天一天,不停的关闭、打开,关闭打开…
经过不知道多少次这样近乎病态式的疯狂训练之后,我觉得我成功了。
之后的一些年里,我差不多无限期的关闭着这个开关,这样我觉得生活不那么沉重了,我觉得轻松。如果有个情绪的电图,那这些年我的情绪电图应该几乎是一条长长而乏味的直线。
然而人毕竟是人啊,和机器不同啊。如果只是仅仅为了活得轻松而舍弃掉所以的情绪,那又有什么意义呢?
所以,做个人吧! 哈哈哈 🙂
现在坐在这里,想着遇见她之后这段时间里一起经历的各种各样的事情和看过的风景,竟然也一时间不知道从何讲起。只是这段时间里,我开始感受到我的情绪了。很开心。原来生活或许不如意事十之八九,却依然让我觉得值得和美好!
总之,感谢生活,感谢大刘,感谢她 🙂
到这里,2021年底的这篇扯淡基本该结束了。上、下这两篇里算是把我这一年的感悟和改变理了七七八八了。后面的日子里,继续保持这自己的节奏,猥琐发育吧!
共勉:永远要保持自己的节奏!
以上。
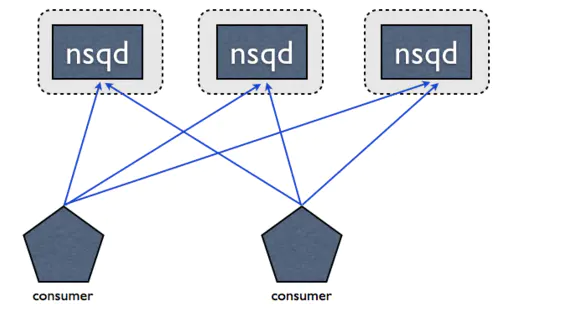
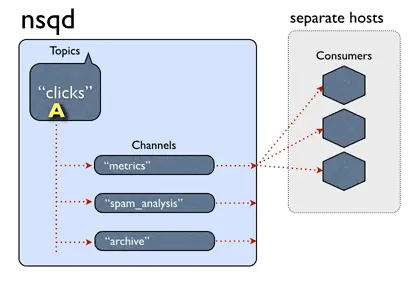
kafaka
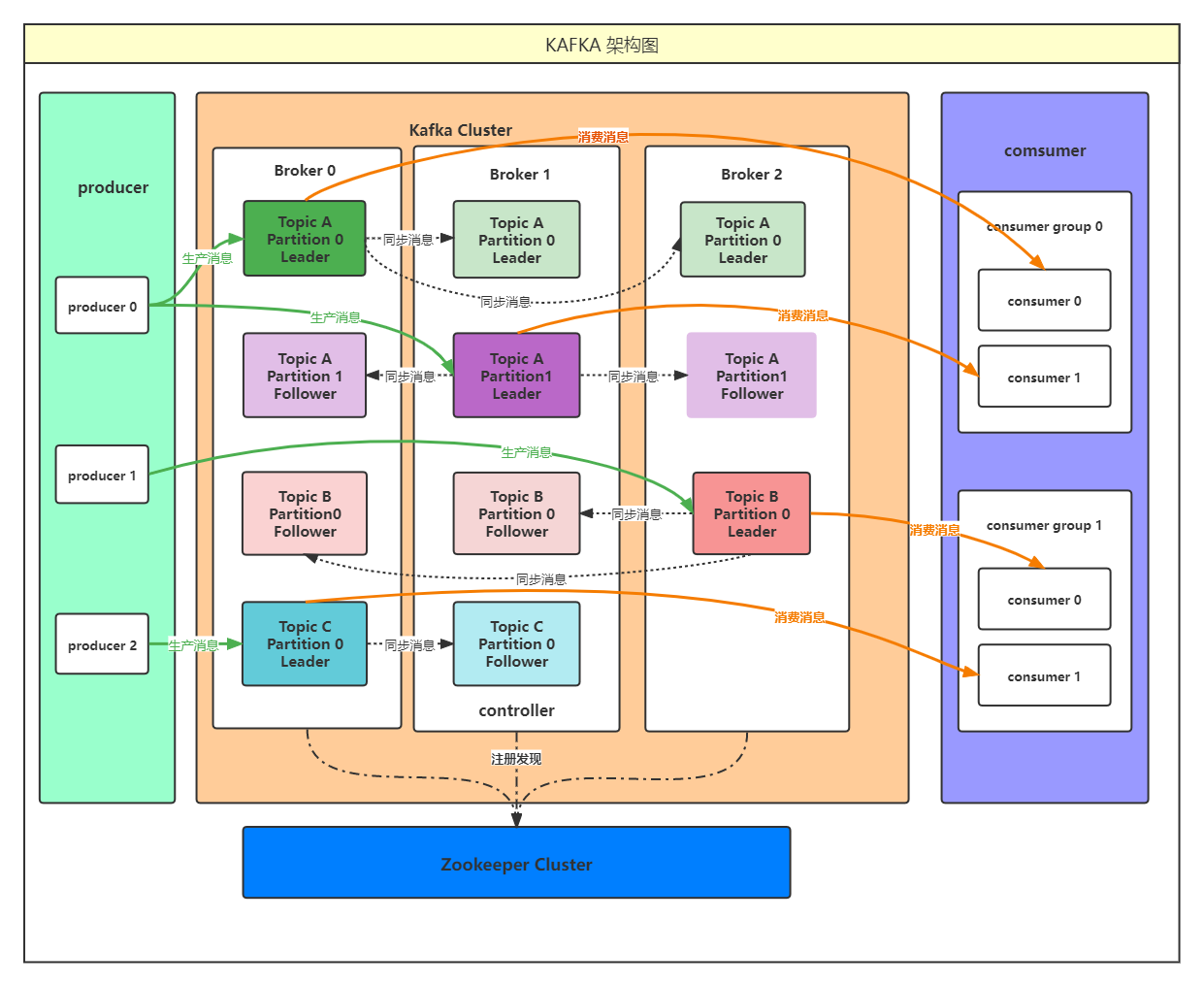
kafka 架构图
关于Kafka 的问题
kafka 是怎么做到 高吞吐率、速度快的?
顺序读写
partition 并行处理
Page Cache
零拷贝

mmap、sendfile
- Producer生产的数据持久化到broker,采用mmap文件映射
- Customer从broker读取数据,采用sendfile,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
用户缓冲区、内核缓冲区、socket buffer、NIC buffer
定期 flush 到磁盘
分区分段+索引
数据压缩
批量读写
kafka 如何保证不重复消费又不丢失数据?
首先我们要了解的是message delivery semantic 也就是消息传递语义。
这是一个通用的概念,也就是消息传递过程中消息传递的保证性。
分为三种:
最多一次(at most once):
消息可能丢失也可能被处理,但最多只会被处理一次。
可能丢失 不会重复至少一次(at least once): 消息不会丢失,但可能被处理多次。
可能重复 不会丢失精确传递一次(exactly once): 消息被处理且只会被处理一次。
不丢失 不重复 就一次
而kafka其实有两次消息传递,一次生产者发送消息给kafka,一次消费者去kafka消费消息。
两次传递都会影响最终结果,
两次都是精确一次,最终结果才是精确一次。
两次中有一次会丢失消息,或者有一次会重复,那么最终的结果就是可能丢失或者重复的。
分布式存储
producer 端
幂等的producer(idempotent producer)
Kafka 的 ISR 机制
所以如果要让写入 Kafka 的数据不丢失,你需要保证如下几点:
每个 Partition 都至少得有 1 个 Follower 在 ISR 列表里
每次写入数据的时候,都要求至少写入 Partition Leader 成功,同时还有至少一个 ISR 里的 Follower 也写入成功,才算这个写入是成功了。
如果不满足上述两个条件,那就一直写入失败,让生产系统不停的尝试重试,直到满足上述两个条件,然后才能认为写入成功。
按照上述思路去配置相应的参数,才能保证写入 Kafka 的数据不会丢失。
参考文献
2021 年底来扯扯淡(上)
最近可能由于工(刀)作(塔)过于辛苦,导致我今天早上闹钟响的时候,只有手醒了。
于是睡过头了。
然后顺手请个半天假。
一套操作感觉就是这么行云流水。
所以现在有时间坐在电脑旁来扯这个淡。
想想2021年马上就要过去了,时间真快啊!
仔细回顾下今年都经历了啥呢?好像大的分界点是从年中6月份项目组解散开始的吧。如果是在小说里,这个一定是一个很好的故事展开线,哈哈。
6月份的时候,在大家刚结束了上周末的一次常规加班之后的一个周一,领导不出所料的突然宣布:项目组原地爆炸。现在我回过头来看感觉很魔幻。那种感觉就像,你们一队人正在和对面开团:
我方斧王先手果断跳吼直接控住对面所有人!
宙斯直接开大!
sven开大跳上去,准备团灭对面!
然后,停电了!!!
沉默了一会后,大家揪着的一颗心总算了放了下来。因为真实的情况是,斧王sven其实在对面:)。
接下来差不多一个月的时间里,事情的发展和大多数无节操的的IT公司的剧情没什么太大区别:临时抽调一个经验丰富的HR来挨个找大家言辞亲切的谈话,大概的内容也很明白:要么流放到其他项目组,要么自己滚,别想着N+1。
本想着争取一下的,无奈发现孤立无援,领导也来劝:公司也不容易啊。
大家相视而笑,悟了。
再后面的一段时间里,大家有的自谋出路走了,有的迫于无奈接受流放,有的不知所踪。最终,大家都有了光明的穷途。
然后时间就到了7月份。我开始了我长达半年的流放的日子,而且似乎看起来结束的日子还是遥遥无期。
现在细细回想起来,有点塞翁失马的感觉。
这下半年的时间可以说是我从毕业工作到现在,业务工作最少的一段时间了。正是因为这样,我有了大把大把的时间来思考、反思、总结。
最后反思下来的结论是:人不能太闲啊!真的好讽刺啊!
这个时代的节奏过于碎片和快速,使得你渐渐变得已经无法系统性的思考问题。
我们总是为了这样那样的事情左右,为了眼前的问题寻找临时性的救火方案。这是一个漩涡陷阱,让所有深陷其中的人终日疲于奔命,无法停下,也无法逃脱。而这就是我这近十年的工作和生活状态啊!
每年,每月,每一天,我就在这个漩涡中努力的前进着以保持自己不会被吞噬。这样的日子不停歇的循环往复着,就像那个一日囚里的人一样。庆幸的是,心里也一直有着挣脱的期盼和希望,总觉得这些都是暂时的,会有那么一天事情会迎来转机。这些年的日子里,竟然就是靠着这个近乎盲目的信念支撑着走了过来。
而且,似乎还要这么走下去。
这就是生活的真相啊!一切并不会想电影里演的那样励志:突然有一天,主角有了奇遇一切都开挂般的好了起来。一切似乎都没么变化。
然后,项目黄了。这个漩涡似乎?竟然?真的停了下来。
经过短暂的眩晕之后,我发现自己很快的适应了起来。
这期间,我也终于第一次完整的看完了一届TI。当然,其中详情就不去过多描述了,总之全村的希望最后败给了一个颠勺的大厨,就是这么简单。
然后,经过了几天的短暂抑郁之后,我发现好像悟了!
因为,我突然发现我姓张,张三的张。
张三说:人要接受自己的有限性。
这种感觉很奇妙。这个事情对我来说,就好像是我在打野的时候突然插了个眼在高台上。我感觉自己的生活突然明亮了起来,视野清晰!
人甚至一下子变得洒脱起来,一种莫名其妙的自信油然而生!我感觉自己浑身充满了能量!
我隐隐的感觉到:我到6了!
于是,我开始试着把重心从工作转移到生活中去。我发现没有996,没有那些感动自己、缓解领导焦虑的加班,天也没有塌下来。我开始慢慢体会到了什么是真实感。
生活,也慢慢的变得美好起来。
未完,待续。
golang断言:一个蛋疼的处理场景
这一切都来源于一个蛋疼的需求场景处理:
因为历史原因,一个需要用到的JSON数据被整个缓存进Redis的一个key中,大概如下:
1 | 127.0.0.1:6379> get dt |
这里还是做了脱敏处理,实际的情形JSON的层级更深…
格式化显示的JSON结构大概是这样:
1 | { |
现在要做的是: address 里的每个元素的 url 字段需要更新。
现在知道的是:address 的值 是一个数组,数组的每个元素是一个map[string]interface{} 类型,map里的元素除了 “url”: “xxx.mp4”, 其他的数量不确定
实现代码大概如下(方便展示,省略了Redis读写的步骤):
1 | detailByte := []byte(`{"address":[{"duration":90,"format":"mp4","url":"xxx.mp4","ext":"{\"key\":\"val\"}"},{"duration":90,"format":"mp4","url":"xxx.mp4","ext":"{\"key\":\"val\"}"}],"value":"web"}`) |
运行结果:
1 | before: { |
怎么说呢,实现了感觉又没有真正实现…
哎,蛋疼。
而今天是你剩余人生的开始
在最后
总会看见自己
你一直知道
那是尽头
也是开始
并发安全&锁&原子操作&CAS&MESI
“是时候好好理清那些重要的基础概念和系统知识了” ——很久之后,当你从泥泞的业务项目代码中脱身时,总是会这样想到。
本文主要是对阅读过的一些好的博客文章做一个汇总整理(参考博客地址见文章末尾),为了查阅方便,以及防止哪天这些博客的文章意外不见
很长时间以来,对于锁&原子操作这些概念术语总是理解的很模糊,知其然不知所以然。想尽量的理清它们在通常意义上在大家口中所指的含义,以后沟通或者看相关的文章都可以节省一些成本。
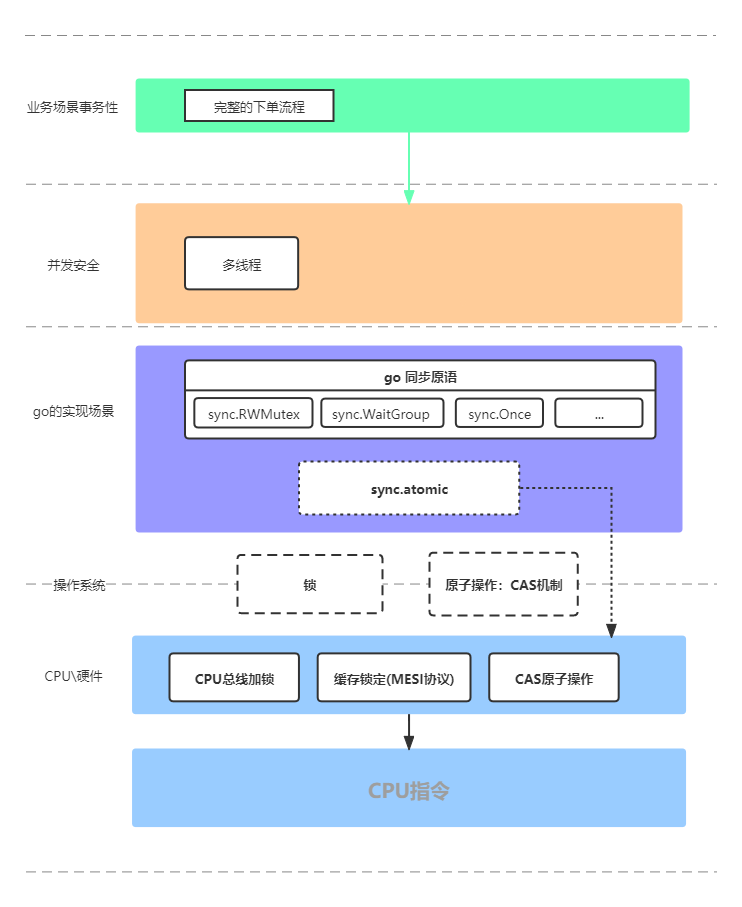
基于这些搜罗了一些这方面的博客和文章,加上自己的理解,基于 Golang 对于其中的一些基础概念和关系的总结。
一图胜千言:
参考博客:
Go之深入理解mutex:http://blog.newbmiao.com/2020/07/01/dig101-golang-understanding-mutex.html
Golang中的CAS原子操作 和 锁:https://blog.haohtml.com/archives/25881
Golang WaitGroup 原理深度剖析:https://www.cyhone.com/articles/golang-waitgroup/
Dig101-Go之聊聊struct的内存对齐:http://blog.newbmiao.com/2020/02/10/dig101-golang-struct-memory-align.html
一文彻底搞懂CAS实现原理 & 深入到CPU指令:https://zhuanlan.zhihu.com/p/94976168
MESI:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
Linux 下关于: select、poll、epoll
“是时候好好理清那些重要的基础概念和系统知识了” ——很久之后,当你从泥泞的业务项目代码中脱身时,总是会这样想到。
本文主要是对阅读过的一些好的博客文章做一个汇总整理(参考博客地址见文章末尾),为了查阅方便,以及防止哪天这些博客的文章意外不见
Table of Contents
前言
在进行解释之前,首先要说明几个概念:
用户空间和内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存处理机上下文,包括程序计数器和其他寄存器。
2. 更新PCB信息。
3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4. 选择另一个进程执行,并更新其PCB。
5. 更新内存管理的数据结构。
6. 恢复处理机上下文。
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。**当进程进入阻塞状态,是不占用CPU资源的**。
文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
正文
select,poll,epoll都是IO多路复用的机制。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间
select
基本原理
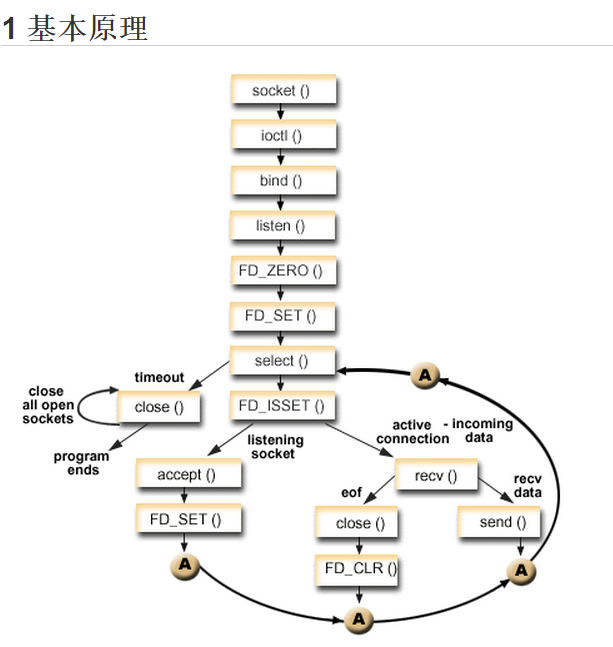
1 | int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); |
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
优缺点
优点:select目前几乎在所有的平台上支持
缺点:
1.单个进程能够监视的文件描述符的数量存在最大限制。
在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低。
2.对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低。
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3.需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
poll
poll基本原理
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
优缺点
优点:没有最大连接数的限制,原因是它是基于链表来存储的。
缺点:
1. 大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2. poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
1 | int poll (struct pollfd *fds, unsigned int nfds, int timeout); |
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll
基本原理
epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll的优点:
1.没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)。
2. 效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3.内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
epoll操作过程需要三个接口,分别如下:
1 | int epoll_create(int size); //创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 |
1. int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符fd执行op操作。
- epfd:是epoll_create()的返回值。
- op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)
- epoll_event:是告诉内核需要监听什么事,struct epoll_event结构如下:
1 | struct epoll_event { |
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待epfd上的io事件,最多返回maxevents个事件。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
epoll的工作模式
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
LT模式:
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的。
当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式
当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
ET(edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
select、poll、epoll对比
进程所打开最大连接数
select
单个进程所能打开的最大连接数有FD—SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上
FD—SETSIZE为32*64) ,当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的
epoll
虽然连接数有上限,但是很大, 1G内存的机器上可以打开10万左右的连接, 2G内存的机器可以打开20万左右的连接
FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历select
速度慢的“线性下降性能问题”
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃
的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll
epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
epoll通过内核和用户空间共享一块内存来实现的。
附录
参考博客: